







U-Story
“솔트룩스, 정치인 소셜분석 사이트 오픈”이라는 기사를 보면서 묘한 느낌이 들었습니다.
제가 2009년부터 여러 곳에 강의를 다니면서 사용했던 단어 중 하나가 스토리입니다. 최근 SNS를 통해서 온라인 컨텐츠가 폭증하면서 ‘빅데이터’라는 용어를 사용하기 시작했는데, ‘빅데이터’ 안에 있는 데이터 하나 하나는 사실 ‘손님’들이 직/간접적으로 경험한 ‘이야기’이기때문에 스토리라는 용어를 사용했었습니다.
와이즈넛, 오픈베이스, 코난테크놀로지 등 대부분의 검색엔진 업체들이 이미 OMS(Opinion Mining Service)시장에 뛰어들었는데, 시멘틱과 언어처리 관련 기술을 보유하고 있는 솔트룩스도 이제 도전을 시작하는 것 같습니다.
솔트룩스 트루스토리

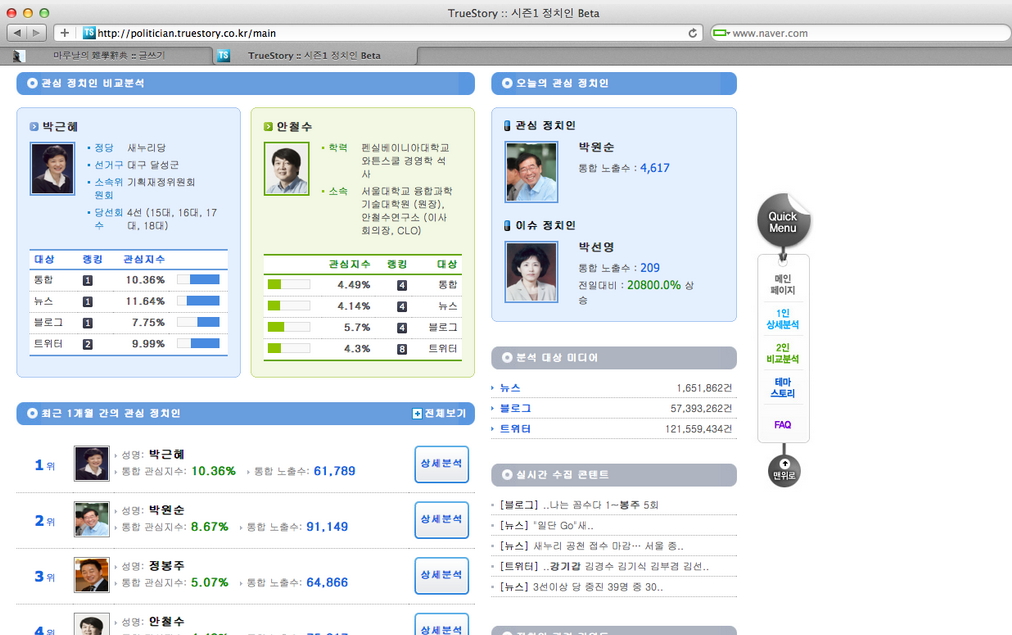
관심지수
제가 추측하기에는 우선 정치인과 관련 키워드로 수집한 컨텐츠의 건수, 조회수(알 수 있다면), 댓글수, 트랙백수, 멘션, RT건수 등의 추가 데이터를 조합하여 만들어내었을 것 같습니다. 랭킹을 보면 관심지수를 만들어내는 수식에서 건수의 영향이 너무 큰 것으로 보여지는데요.
이 부분은 채널(뉴스, 블로그, 트위터)에 따른 가중치 적용이 되어 있지 않거나 조정이 필요한 부분이 아닌가 생각됩니다.물론 뉴스로 기사화되거나 트위터에 언급이 많이 되는 것도 관심이기는 합니다만 단순히 언론이나 트위터에 많이 나온 것을 지수화하는 것은 큰 의미가 없기 때문입니다.
노출수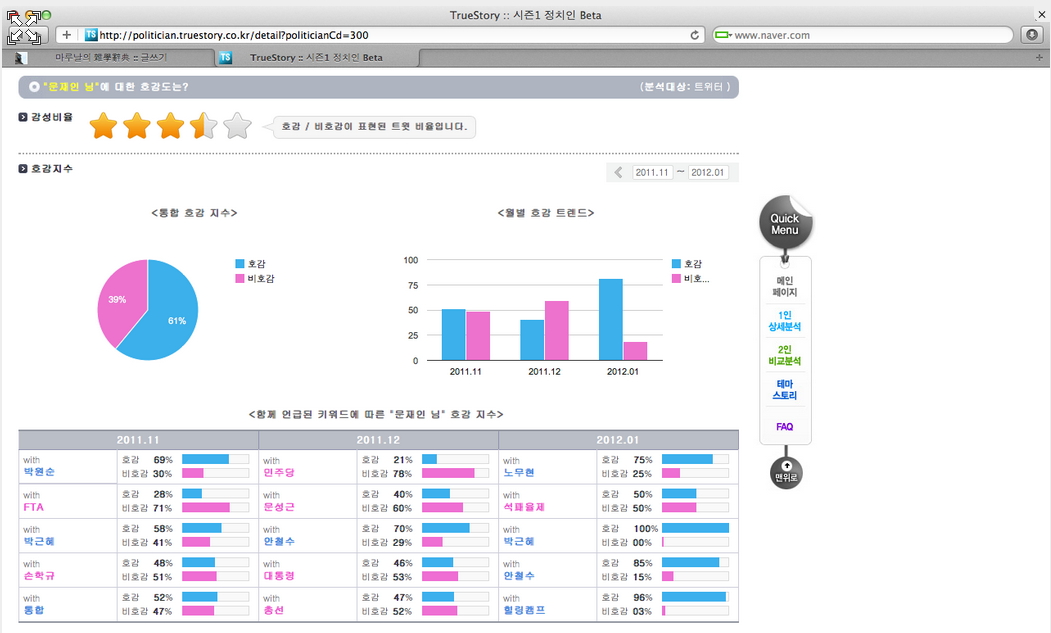
관심지수를 뽑기 위한 컨텐츠의 건수, 조회수(알 수 있다면), 댓글수, 트랙백수, 멘션, RT건수 등의 데이터에 대한 가중치를 포함한 총합으로 보여집니다.
감성비율
솔트룩스는 시멘틱과 언어처리 관련 기술을 보유하고 있는 회사이기때문에 수준이 어느정도인지는 모르지만 트위터만 대상으로 보여주는 것을 보면 단순한 문장에서 sentiment를 뽑아내는 것은 자동화가 되고 나머지는 여전히 사전작업 등이 필요한 시스템같습니다.
기타
호감지수와 함께 언급된 키워드에 따른 호감지수가 그나마 의미있는 결과인데, 사실 sentiment를 뽑으려면 키워드와 키워드의 관계도 분석할 때 고려해야 하기때문에 자연스럽게 결과가 분석된 것 같습니다.
그렇다면,
사실 모든 이야기에는 긍정/부정/Mixed/일반 등으로 구분할 수 있는 tonality가 있는데, 이를 긍/부정으로 구분하게 되면 노출과 관련된 데이터와 조합하여 실제적인 지지도에 근접한 데이터를 끄집어 낼 수 있습니다. 이 서비스에서는 베타이고 맛보기여서 핵심적인 지표는 보여주고 있지 않은데 그나마 호감지수가 근접한 지표로 보입니다.
OMS 비즈니스를 성공적으로 이끌어 가기 위해서는 빅데이터를 잘 수집해서 분석하여 데이터를 뽑아주는 것이 전부가 아닙니다. 오히려는 데이터를 분석하는 것에 집중하게되면 나무만 잘 그리고 숲을 보지 못하는 우를 범할 수 있습니다.
데이터를 정교하게 뽑는 것은 기본이고 중요하지만, 결론을 내려주고 방향을 잡아 줄 수 있어야 합니다. 물론 분석결과를 해석하는 것은 손님의 몫이라고 할 수 있습니다만, OMS를 통해서 뽑혀지는 데이터는 특성상 개별적으로는 매우 정확하지만 전체 그림을 그리고 맥락을 이해하기에는 어렵습니다.
구슬이 서말이어도 꿰어야 보석이라는 말처럼 왜 관심지수가 높은지 또는 왜 호감지수가 낮은지 등과 같은 이야기를 해 줄 수 있는 총괄적인 지표를 만들어야 할텐데 이 부분은 지금까지 가지고 있는 기술과 조금 다른 분야이기도 합니다.
아무튼 쉽지 않은 비즈니스를 시작하셨는데요. 솔트룩스의 빛나는 보석을 보고 싶습니다. 화이팅!
글 : 마루날
출처 : http://ithelink.net/866