구글이 사진에 나온 장면을 문장으로 묘사할 수 있는 소프트웨어를 개발했다고 Google Research Blog를 통해 밝혔다. 이는 아직 연구 초기 단계에 있는 기술로, 구글에서는 이 기술을 학술 논문을 통해 ‘A Neural Image Caption Generator‘라고 표현했다.
구글의 이번 연구는 ‘사진 속에서 어떤 일이 벌어지고 있는지’, ‘다양한 사물들 간에 어떤 관련이 있는지’와 같은 이미지에 나타난 전반적인 상황을 읽어내고 이를 자연스러운 언어로 표현해낸다는 데에서 그간 많은 연구가 선행되어온 컴퓨터 비전(Computer Vision) 분야에 있어 의미 있는 발전이라고 할 수 있다.
가령, 구글의 새로운 소프트웨어는 ‘야외 시장에서 한 무리의 사람들이 장을 보고 있다’와 같이 사진에 나타난 모습을 짤막한 문장으로 묘사할 수 있을 뿐만 아니라, ‘가스레인지 위에 피자 두 개가 올려져 있다’처럼 사물의 수를 셀 수도 있다고 한다. 그러나 구글 연구팀은 이러한 소프트웨어 연구 및 개발은 거의 초기 단계에 머물러 아직 한계가 많다고 전하기도 했다.

오류 정도에 따라 분류된 구글 이미지 묘사 소프트웨어의 결과물 (출처:Google Research Blog)
구글 연구팀이 밝힌 바에 따르면, 이 새로운 소프트웨어는 서로 다른 용도를 가지고 별도로 개발된 두 개의 네트워크를 연결하는 일종의 ‘디지털 뇌 수술(digital brain surgery)’을 통해 개발되었다고 한다. 그중 하나의 네트워크는 물체를 식별하기 위한 용도로 이미지의 내용을 수학적 기호로 가공하도록 훈련된 것이고, 다른 하나는 자동 번역 소프트웨어의 일종으로 완벽한 영어 문장을 생성하기 위한 용도로 훈련된 것이다. 이러한 두 가지 네트워크의 결합을 통해 구글의 새로운 소프트웨어가 탄생할 수 있었다.
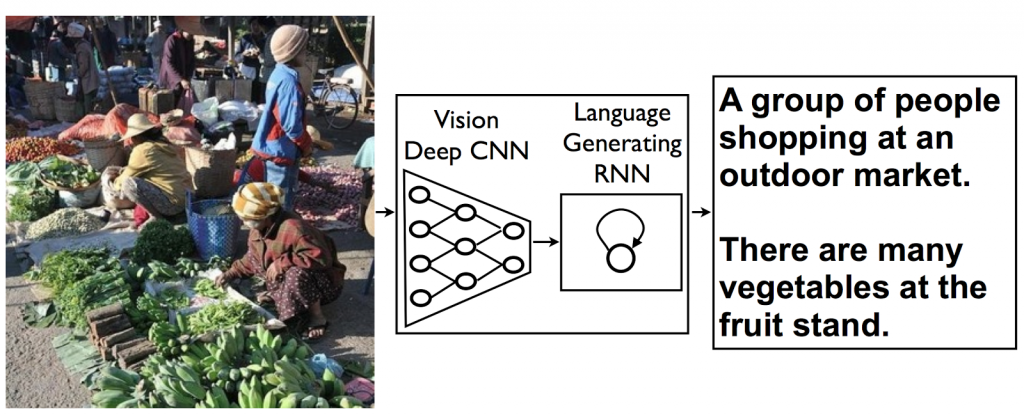
구글의 새로운 소프트웨어가 이미지를 하나의 문장으로 묘샤하는 원리 (출처:Google Research Blog)
구글 연구팀은 이러한 소프트웨어 시스템을 통해, 시각 장애우들이 사진을 보지 못하더라도 그 속에 담긴 내용을 이해할 수 있도록 할 수 있을 뿐만 아니라, 향후 구글에서 이미지를 검색하는 것이 더욱 쉬워질 것이라고 전망했다.
구글의 이번 연구에 대한 상세한 내용은 여기에서 볼 수 있다.
인턴 박선민 (sunmin2525@venturesquare.net)
You must be logged in to post a comment.